canal集群有2种方式部署,分别是采用canal-admin集中管理配置文件和本地存储配置文件的方式,canal-admin方式配置比较方便,有变更只需要修改canal-admin中保存的配置即可,而本地保存配置文件的方式就是需要在集群所有节点都要配置一份相同的配置文件,这种方式不依赖canal-admin
当前以canal-admin方案为例
1、canal-admin部署
部署服务器:csc-nacoszk-1
canal-admin路径及配置文件
[root@csc-canal-admin canal-admin]# pwd
/data/canal-admin
[root@csc-canal-admin canal-admin]# ls
bin conf lib logs
[root@csc-canal-admin canal-admin]#
application.yml文件配置
[root@csc-canal-admin conf]# pwd
/data/canal-admin/conf
[root@csc-canal-admin conf]# ls
application.yml canal_manager.sql instance-template.properties public
application.yml.bk canal-template.properties logback.xml
[root@csc-canal-admin conf]# cat application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 172.20.21.88:3306
database: canal_manager
username: canal
password: Aa1234@abcd
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
[root@csc-canal-admin conf]#
上文配置了mysql数据库的地址和用户名密码,还有访问web页面的用户名admin等信息,下一步需要导入初始化sql文件
[root@csc-canal-admin conf]# pwd
/data/canal-admin/conf
[root@csc-canal-admin conf]# ls
application.yml canal_manager.sql instance-template.properties public
application.yml.bk canal-template.properties logback.xml
[root@csc-canal-admin conf]#
canal_manager.sql 为需要导入的文件,导入到数据库后启动服务
[root@csc-canal-admin bin]# pwd
/data/canal-admin/bin
[root@csc-canal-admin bin]# ls
admin.pid restart.sh startup.bat startup.sh stop.sh
[root@csc-canal-admin bin]# ./startup.sh &
[root@csc-canal-admin bin]#
服务监听8089端口,通过上文配置的admin用户登录,之后找到集群管理
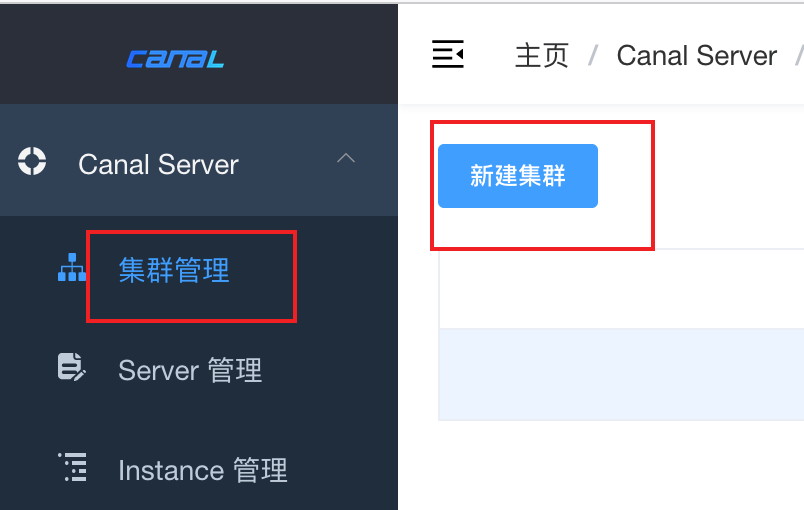
新建集群,填写集群名字,这个名字要记得,后面配置集群节点要用到,还要填写zookeeper地址
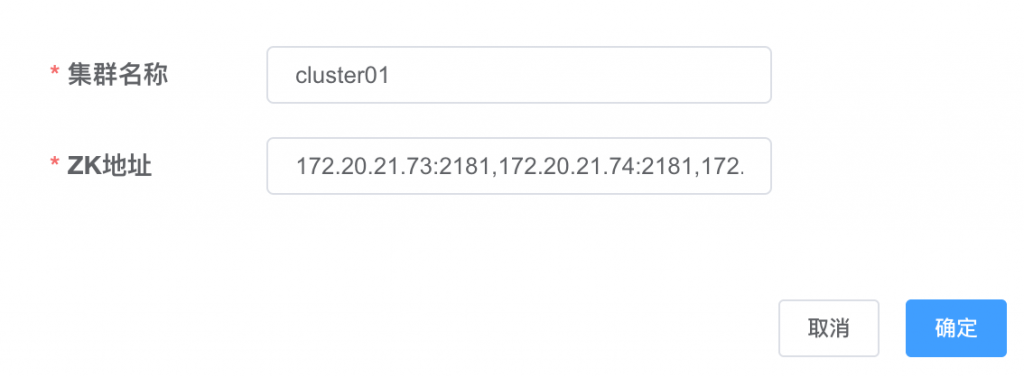
然后点击集群名字后面的操作,修改主配置
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers = 172.20.21.73:2181,172.20.21.74:2181,172.20.21.75:2181
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = manager
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
canal.instance.global.spring.xml = classpath:spring/group-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:6667
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
#rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
如果一个instance中需要配置多个数据源,最好将下面的这行注释打开,并对这个文件配置,具体配置可以参考canal-deployer
canal.instance.global.spring.xml = classpath:spring/group-instance.xml
修改对应的实际环境的ip、端口、用户名等信息保存,再导航到server管理项,右侧新建server
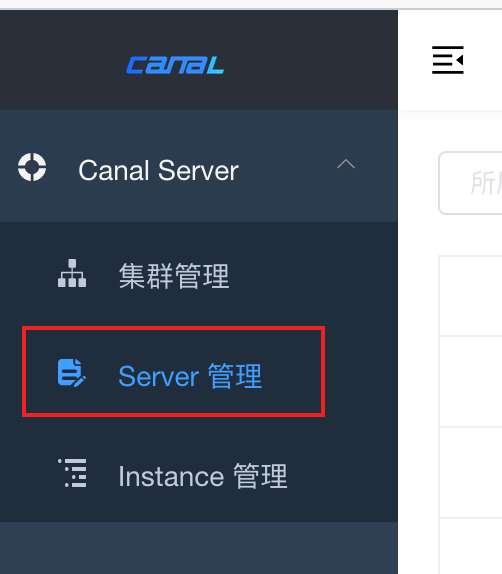
将三台canal-deployer加入进来
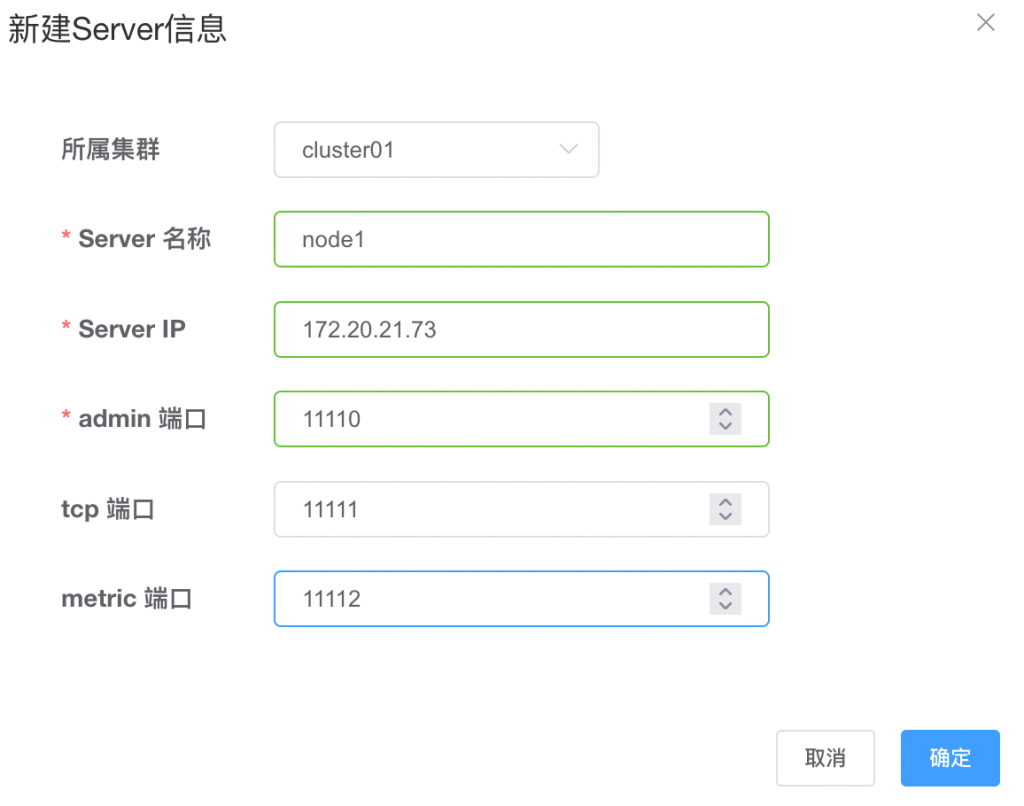
添加完成后可以通过后面操作对节点进行启动停止等维护操作
添加instance,instance管理–>新建instance
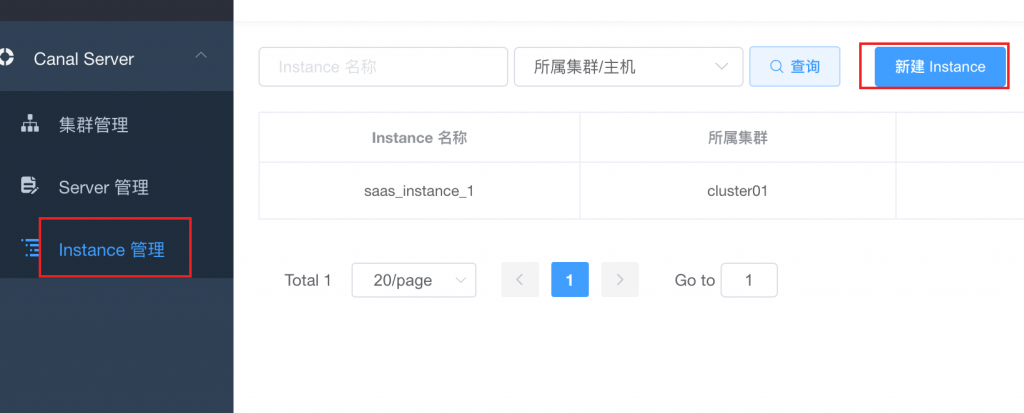
名称根据实际情况填写
#################################################
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId=130
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master1.address=172.20.21.88:3306
canal.instance.master1.journal.name=
canal.instance.master1.position=
canal.instance.master1.timestamp=
canal.instance.master1.gtid=
canal.instance.master2.address=172.20.21.89:3306
canal.instance.master2.journal.name=
canal.instance.master2.position=
canal.instance.master2.timestamp=
canal.instance.master2.gtid=
canal.instance.master3.address=172.20.21.90:3306
canal.instance.master3.journal.name=
canal.instance.master3.position=
canal.instance.master3.timestamp=
canal.instance.master3.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=sharding_slave
canal.instance.dbPassword=Aa1234@abcd
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=saas_instance_1
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
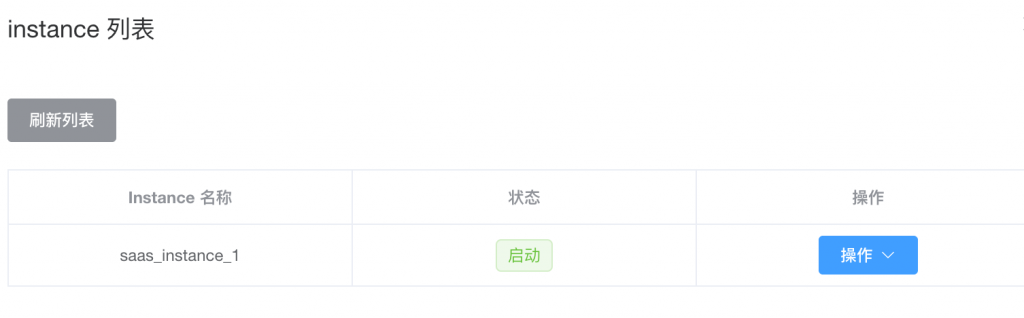
修改ip和端口后保存,然后对其进行启动操作

可以通过节点的详情功能查看instance运行在哪台服务器
2、canal-deployer部署
部署服务器:csc-nacoszk-1,csc-nacoszk-2,csc-nacoszk-3,这三台需要部署的服:canal-deployer, canal-adapter
canal-deployer路径及配置文件
[root@csc-canal1-zookeeper1 deployer]# pwd
/data/deployer
[root@csc-canal1-zookeeper1 deployer]# ls
bin conf lib logs plugin
instance.properties文件配置
[root@csc-canal1-zookeeper1 deployer]# cd conf/example
[root@csc-canal1-zookeeper1 example]# pwd
/data/deployer/conf/example
[root@csc-canal1-zookeeper1 example]# ls
h2.mv.db h2.trace.db h2.trace.db.old instance.properties meta.dat
[root@csc-canal1-zookeeper1 example]# grep -Ev "^#" instance.properties | grep -Ev "^$"
canal.instance.mysql.slaveId=1
canal.instance.gtidon=false
canal.instance.master.address=172.20.21.88:3306
canal.instance.tsdb.enable=true
canal.instance.dbUsername=canal
canal.instance.dbPassword=Aa1234@abcd
canal.instance.connectionCharset = UTF-8
canal.instance.enableDruid=false
canal.instance.filter.regex=.*\\..*
canal.instance.filter.black.regex=mysql\\.slave_.*
canal.mq.topic=example
canal.mq.partition=0
[root@csc-canal1-zookeeper1 example]#
canal.properties文件配置
[root@csc-canal1-zookeeper1 conf]# pwd
/data/deployer/conf
[root@csc-canal1-zookeeper1 conf]# ls
canal_local.properties canal.properties.bk logback.xml metrics spring canal.properties example logback.xml_bak
[root@csc-canal1-zookeeper1 conf]# grep -Ev "^#" canal.properties | grep -Ev "^$"
#每台服务器的canal的ID不能相同
canal.id = 1
#填写本机ip
canal.ip = 172.20.21.73
canal.port = 11111
canal.metrics.pull.port = 11112
#填写canal-admin的地址
canal.admin.manager = 172.20.21.76:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.admin.register.auto = true
#加入的集群名称,在canal-admin中配置的
canal.admin.register.cluster = cluster01
canal.admin.register.name = node1
#zookeeper地址
canal.zkServers = 172.20.21.73:2181,172.20.21.74:2181,172.20.21.75:2181
spring/group-instance.xml
[root@csc-canal1-zookeeper1 spring]# pwd
/data/canal-deployer/conf/spring
[root@csc-canal1-zookeeper1 spring]# ls
base-instance.xml file-instance.xml group-instance.xml.bak tsdb
default-instance.xml group-instance.xml memory-instance.xml
[root@csc-canal1-zookeeper1 spring]#
配置文件中添加配置如下:
<bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.group.GroupEventParser">
<property name="eventParsers">
<list>
<ref bean="eventParser1" />
<ref bean="eventParser2" />
<ref bean="eventParser3" />
<ref bean="eventParser4" />
</list>
</property>
</bean>
还要针对各个eventParser配置:
将
<bean id="eventParser1″ parent="baseEventParser">
这样的标签配置数量和上面的eventParser相同,标签中有对应的master和standby也要修改成和eventParser的编号相同
配置完成启动服务
[root@csc-canal1-zookeeper1 bin]# pwd
/data/deployer/bin
[root@csc-canal1-zookeeper1 bin]# ./startup.sh &
可以通过查看这些端口观察服务器是否启动:11111,11112
- canal-adapter部署 部署服务器:csc-nacoszk-1,csc-nacoszk-2,csc-nacoszk-3
canal-adapter路径及配置文件
[root@csc-canal1-zookeeper1 adapter]# pwd
/data/adapter
[root@csc-canal1-zookeeper1 adapter]# ls
bin conf lib logs plugin
[root@csc-canal1-zookeeper1 adapter]#
application.yml文件配置
[root@csc-canal1-zookeeper1 conf]# pwd
/data/adapter/conf
[root@csc-canal1-zookeeper1 conf]# ls
application.yml bootstrap.yml es6 es7 logback.xml META-INF
[root@csc-canal1-zookeeper1 conf]# grep -Ev "^#" application.yml | grep -Ev "^$"
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
zookeeperHosts:
syncBatchSize: 1000
consumerProperties:
canal.tcp.server.host: 172.20.21.73:11111
#下面的配置是测试用的,生产环境需要根据项目要求配置
srcDataSources:
defaultDS:
url: jdbc:mysql://172.20.21.88:3306/testdb?useUnicode=true&useSSL=false
username: canal
password: Aa1234@abcd
canalAdapters:
#instance名称,对应canal-admin中的instance名称
- instance: example
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es7
key: saas
hosts: http://172.20.21.84:9200
properties:
mode: rest
cluster.name: es
[root@csc-canal1-zookeeper1 conf]#
在es7目录下创建数据库读取文件,这里以test.yml文件为例
[root@csc-canal1-zookeeper1 es7]# pwd
/data/adapter/conf/es7
[root@csc-canal1-zookeeper1 es7]# ls
test.yml
[root@csc-canal1-zookeeper1 es7]# cat test.yml
#对应application.yml中的数据源
dataSourceKey: defaultDS
#对应application.yml中的key
outerAdapterKey: saas
#对应application.yml中instance名称
destination: example
groupId: g1
esMapping:
_index: canal_test
_id: id
_type: _doc
sql: "SELECT id, name, age FROM users"
etlCondition: "where open_time>={}"
commitBatch: 3000
下一步需要去kibana上创建es的索引,因为是测试环境,用的mysql表数据也比较简单,数据库表结构:

在kibana控制台窗口上创建索引:因为已经创建过canal_test,所以这里用canal_test2做演示
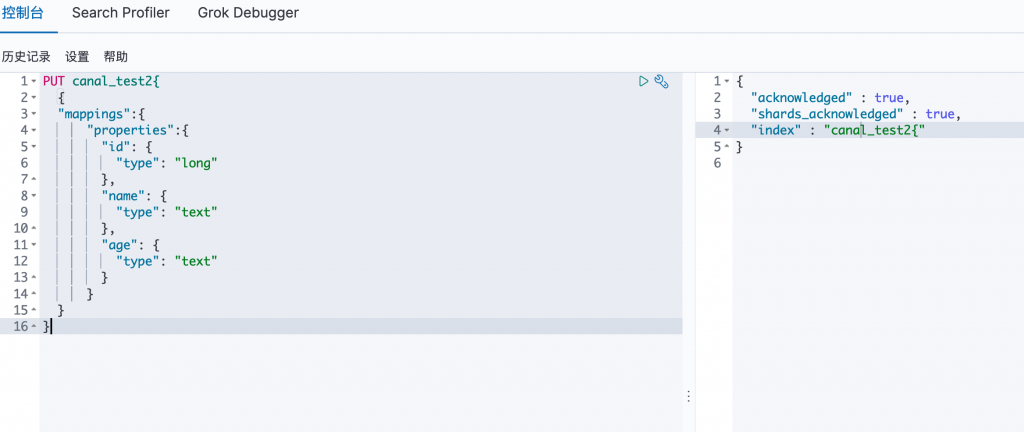
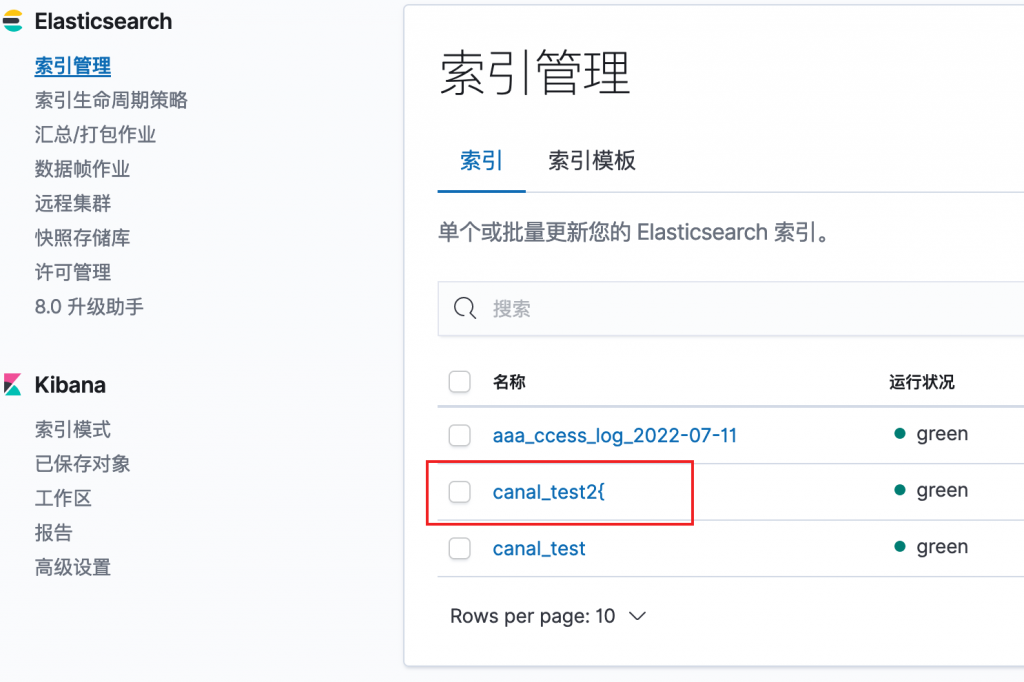
在索引管理里面可以只要能查看到刚才创建的索引即可
下一步启动服务
[root@csc-canal1-zookeeper1 bin]# pwd
/data/adapter/bin
[root@csc-canal1-zookeeper1 bin]# ls
adapter.pid restart.sh startup.bat startup.sh stop.sh
[root@csc-canal1-zookeeper1 bin]# ./startup.sh &
[root@csc-canal1-zookeeper1 bin]#
手动更新方式
curl -X POST http://127.0.0.1:8081/etl/es7/test/test1.yml
#127.0.0.1:8081 adapter地址和端口
#etl 固定格式
#es7 /data/canal-adapter/conf下保存yml文件的目录名称
#test application.yml中canalAdapters:key的名称
#test1.yml es7目录下的yml文件名
curl -X POST http://127.0.0.1:8081/etl/es7/test/test1.yml?params=“aaa”
#?params=“aaa” 可以给yml文件传参数,yml文件中用{}来接收该参数,多个参数用;隔开